")


")

")
A summary of the interesting articles I've found this month.
Why Puppet/Chef/Ansible aren't good enough (and we can do better): This is mostly about the Nix package manager and the new linux distro NixOS which is entirely Nix-based down to the bone. I haven't used it yet, but I had to admit this is what I was trying to achieve back in the 1990s with the simple package management system I made... but I didn't go far enough. These people did. I'm looking forward to trying this out.
http://dec64.com DEC64 is a new (proposed) floating point format. I fear that most people don't understand how floating point numbers are stored on computers so this will be wasted. However I'm fascinated by the implications of this new (proposed) format. Basically 54-bits are used to store an integer and 8 bits are used to store the exponent. So, you know how big numbers are often written "1234E45"? Well, in this format you store "1234" in the 54-bit part and "45" in the 8-bit part. If two numbers have the same exponent the math is just integer math (assuming no overflow).
Multipath TCP: I had misconceptions about this. It turns out this is a system for doing TCP over all your interfaces at the same time. For example, a mobile phone has a Wifi NIC and an LTE "modem". MPTCP let's you open a connection to a web site on Wifi and LTE at the same time, load balancing between the two; transparently switching between them as one has more errors or dropouts, etc. I think this would make my mobile experience so much better that I plan on changing mobile platforms the moment someone supports this. Of course, it has to be supported on the website end also, but I can hope. Evil thought: The IPv6 people should convince kernel developers to only implement this for IPv6 and declare it to the "the killer feature of IPv6". Considering that LTE is IPv6, this isn't too far fetched.
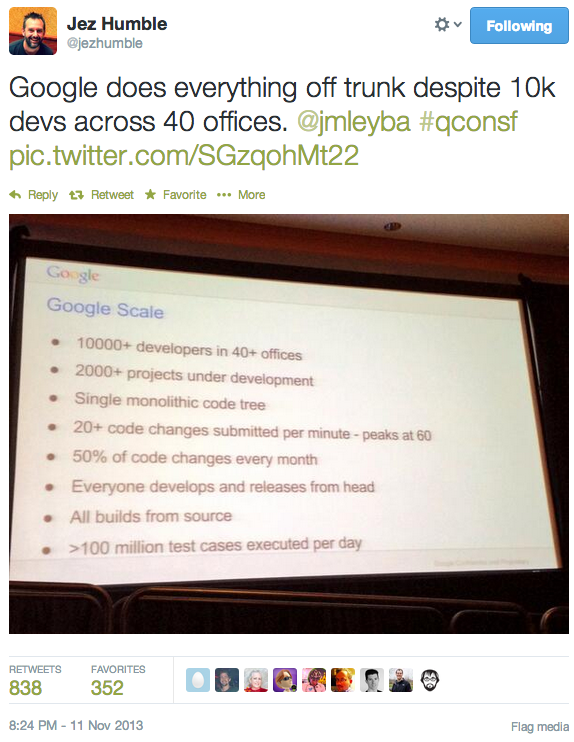
Looking back on "Look Back" videos: Facebook is doing some interesting SRE and development work. This is an interesting look inside what they do.
Go Read: One Year with Money and App Engine: When Google Reader was cancelled, Matt made a clone called "Go Read". At the 1 year anniversary here's his look back at his experience building a business and making it profitable. It turns out a key part was optimizing not the code, but his usage of Google App Engine. Interesting quote: "App Engine charges for data stored in its amazing datastore (my favorite feature of App Engine and the only feature I'm aware of that has zero competitors in the cloud space. When you compare to AWS prices, no one mentions the datastore.)"
How We Make Trello: This is a great writeup of how Trello works ... on the inside. It turns out the web client is doing all the smarts in the browser and talks to their API just like the mobile app does. More web apps should be like that. If you aren't using Trello you should check it out. People love it so much that I get fanmail just for recommending it. One of my talks at Cascadia IT 2014 included 3 slides on Trello. The next week I got email that said, "I especially want to thank you for Trello - what a simply elegant app--wish I'd found this sooner--it's a breeze and SO HELPFUL! I've tried other PM tools that I like but that seemed to take too much setup and maintenance time (like Basecamp, etc.). Trello is about as perfect as it gets."
Why Roslyn is a big deal: I'm a total fanboy for reading about compiler internals. If reading about LLVM got you hot and bothered, check out Microsoft's new compiler project. By making the compiler out of re-usable components, it is going to make their IDEs and, heck, their entire tool chain a lot, lot, better. Why aren't the LLVM people applying this kind of thinking to IDEs?