")


")

")
There is often a debate between software developers about whether it is best to branch software, do development, then merge back into HEAD, or just work from HEAD.
Jez Humble and others make the claim that the latter is better. If you make your changes in "small batches" this works. In fact, it works better than branching. When you merge your branch back in the bigger the merge, the more likely the merge will introduce problems.
Jez recently tweeted:
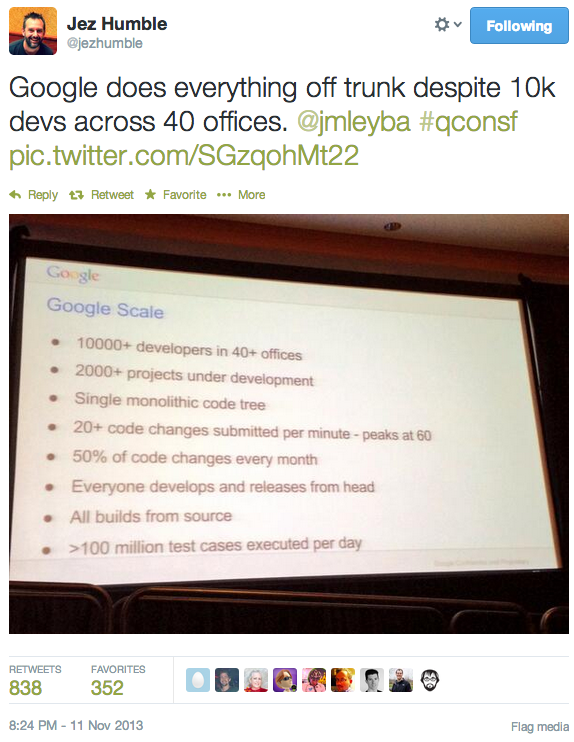
which caused a bit of debate between various twitterers (tweeters? twits?)
Jez co-wrote the definitive book on the subject, so he has a lot of authority in this area. If you haven't read Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (by Jez Humble and David Farley), stop reading this blog post now and get it. Seriously. It is worth it.
Some things I'd like to point out about that slide from Google:
- Yes, 10000 developers all working from HEAD actually works. People often say that this can't possibly scale, and yet here is an example of it working. There's a big difference between "it can't work", "I haven't gotten it to work", and "I'm conjecturing that it couldn't work".
- Even though Google has one big monolithic code tree, each project can be checked out individually. That said, if your project is a library that other people use, compiling at timestamp T means getting the library as it is at timestamp T also.
- Do some projects use a branch-and-merge methodology? When I started at Google some did use "branch and merge". However those numbers were shrinking. I'm sure there were still some that did this, for special edge cases. Not that I had visibility to every project at Google, but it was generally accepted as true that nearly everyone worked from HEAD.
- "50% of code changes every month": A big part of why that is possible is that Google is very aggressive about deleting inactive code. It's still in the VCS's history if you need it, so why not delete it if it isn't being used? By being aggressive about deleting inactive code it greatly reduces the maintenance tax. Making a global change (like.... changing a library interface) is much easier when you only have to do it for active projects.
Of course, what's really amazing about that slide is that the entire company has one VCS for all projects. That requires discipline you don't see at most companies. I've worked at smaller companies that had different VCS software and different VCS repositories for every little thing. I'm surprised at how many companies have entire teams that don't even use VCS! (If there was an Unicode codepoint for a scream in agony, I'd insert that here).
By having one repo for the entire company you get leverage that is so powerful it is difficult to even explain. You can write a tool exactly once and have it be usable for all projects. You have 100% accurate knowledge of who depends on a library; therefore you can refactor it and be 100% sure of who will be affected and who needs to test for breakage. I could probably list 100 more examples. I can't express in words how much of a competitive advantage this is for Google.
In a literal sense not all Google code is in that one tree. When I was there, Chrome, Android and other projects had their own tree. Chrome and Android were open source projects and had very different needs. That said, they are "work from HEAD" so the earlier point is the same.
Tom
Disclaimer: This is all based on my recollection of how things were at Google. I have no reason to believe it hasn't changed, but I have no verification of it either.

We just had this debate at work - it's our first time using a VCS to co manage a project that had been maintained by one guy. We decided it would be easiest to have a "Dev" branch that we share, and roll that into production after testing it.
Does the model I just described match the way Google does things? (I know Chrome has a Canary/Beta branch) Alternatively is the implication that code commits at Google are generally always right into production?
They must have some AMAZING testing tools.