")


")

")
Teams working through The Three Ways need an unbiased way to judge their progress. That is, how do you know "Are we there yet?"
Like any journey there are milestones. I call these "look-for's". As in, these are the things to "look for" to help you determine how a group is proceeding on their journey.
Since there are 3 "ways" one would expect there to be 4 milestones, the "starting off point" plus a milestone marking the completion of each "Way". I add an additional milestone part way through The First Way. There is an obvious sequence point in the middle of The First Way where a team goes from total chaos to managed chaos.
The Milestones
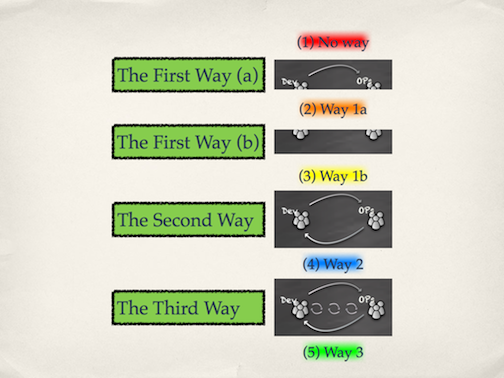
The Look-For's
Milestone 1 (No Way) Look-For's
At this stage you haven't gotten started. You may or may not be doing ok, you don't know because nothing is documented, automated or measured.
- Results are inconsistent.
- Different people execute processes differently.
- Processes aren't documented.
- The team can't enumerate all the processes a team does (even at a high level).
- IT department responsible for "everything with an electric plug" and, therefore, unable to do anything.
- Requests get lost or stalled indefinitely
- Unable to predict how long common tasks take to complete.
- Little or no measurement or metrics.
- No dashboards.
- You think customers are happy but they aren't.
- Operational problems, if reported, don't get attention.
- It is common (and rewarded) to enact optimizations that benefit a person or small group to the detriment of the larger organization or system.
- Departmental goals emphasize departmental performance at the detriment of organizational performance.
Milestone 2 (Way 1a) Look-For's
The end-to-end process is documented and repeatable by more than one person. There are few ad hoc steps (if any exist, they are identified). The system produces relatively consistent results.- End-to-end process has each step enumerated, with dependencies.
- End-to-end process has each step's process documented.
- Different people doing the tasks the same way.
- Sadly, there is some duplication of effort seen in the flow.
- Sadly, some information needed by multiple tasks may be re-created by each step that needs it.
Milestone 3 (Way 1b) Look-For's
The First Way has been achieved. The flow is one direction: left to right (i.e. work doesn't need to go back to be re-done or fixed). Defects are not passed down the line. Process changes are no longer process surprises. We may not be achieving our objectives but at least they are defined. For example we now know we want to have all new service requests done in 48 hours but we may or may not be measuring completion time to know whether or not we are hitting that objective.- Each step has QA checklist before handing off to next step.
- There is a process by which all learn of changes to others' processes (Ex: Ops attends Dev standups; Dev attends Ops meetings.)
- Information needed by multiple steps is created once.
- No (or minimal) duplication of effort.
- Ability to turn-up capacity of flow repeatably.
- ACHIEVEMENT UNLOCKED: THE FIRST WAY
Milestone 4 (Way 2) Look-For's
The Second Way has been achieved. Feedback flows upstream so that the process can be improved and surprises are reduced. Problems are amplified rather than hidden. For each step we measure wait time, task duration, number of defects, and any rework.- There are feedback mechanisms for all steps.
- Oncall pain shared by the people most able to fix problems.
- Dashboards exist showing each step's completion time; lag time of each step.
- Dashboards exist showing current bottleneck, backlog, idle steps.
- Dashboards show defect and rework counts.
- Periodic (weekly?) review of defects and reworks.
- Postmortems published for all to see, draft within X hours, final within X days.
- Periodic review of alerts by affected team. Periodic review of alerts by cross-functional team.
- Process change requests require data to measure problem being fixed.
- Dashboards report data in business terms (i.e. not just technical terms).
- Every "fail-over procedure" has a "date of last use" dashboard.
- Capacity needs predicted ahead of need.
- ACHIEVEMENT UNLOCKED: THE SECOND WAY
Milestone 5 (Way 3) Look-For's
The Third Way has been achieved. There is a culture of experimentation and learning. The team spends more time on innovation than fighting fires. Operations are driven by science, not folklore or guesswork.- After process changes are made, before/after data compared to determine success.
- Process changes are reverted if before/after data shows no improvement.
- Process changes that have been acted on come from a variety of sources.
- At least one process change has come from every step (in recent history).
- Cycle time enjoys month-over-month improvements.
- Mechanisms exist so that any fail-over procedure not utilized in recent history is activated artificially.
- Stress-testing and failover testing done periodicly (quarterly or monthly).
- "Game Day" exercises (intensive, system-wide tests) done periodicly (at least yearly).
- The team employees a statistician.
- Decisions supported by modeling "what if" scenarios using extracted actuals data
- ACHIEVEMENT UNLOCKED: THE THIRD WAY
FAQ
Q: Do I have to do this??
A: DevOps culture is about doing things because there is a need and a problem to be fixed. There are no "rules" for DevOps, only guidelines, best practices and techniques that can be deployed. Contrast this to process-heavy systems encourage people to do things because some book says you have to do them. Such systems often results in management cargo cult where you do things out of blind obligation.
DevOps is a culture, not a system of "rules" that must be blindly obeyed. Therefore these "look for's" are not rules. A team should not try to "check every box". If management gives you a bad performance review because they can't find evidence of everything on the list, they're doing it wrong. These are not the only look for's, there are simply the ones that I have found work for me.
That said, you don't have to eat your vegetables either, but they're good for you. I think self-assessments like this are good for you. (Like... why else would I have written all this?)
Q: What are The Three Ways of DevOps?
A: Gene Kim's "The Three Ways" are the underpinning principles of DevOps. The fastest way to understand them is Tim Hunter's description.
A team that is operating under all three principles has a system that is resilient and change-able. They are confident in their ability to make changes without causing outages or other problems. This confidence enables experimentation. Innovation comes from trying new things. Therefore most of the team's energy can and is spent on innovation through experimentation.
The opposite is a team focused on fire-fighting. Nobody has time for making the big improvements because everyone is so focused on keeping the ship from sinking. Rather than a culture of innovation it is a culture of chaos and despair.
Q: Why did you split The First Way into two parts?
A: The first way is such a long journey itself I think this is justified. The first half is "getting the system working" and the second half is "defining expectations". In the first half we get the flow right (the steps are documented so that everyone is doing them the same way); the other half we've completed the rest of The First Way (business objectives have been defined). We may not be meeting those business objectives, but at least the process is solid enough that we can define them.
Q: These "look-for's" are all wrong. I have better ones.
A: I'm sure you do. These aren't "rules". This is what works for me. I'd love to add your look-for's to this page. Feel free to email me or post a comment.
Q: What's this "left-to-right" business?
A: Most processes have a sequence of steps. List teach step as a column on a Kanban Board. As a "work item" completes a step, it moves to the next column. That is, it moves to the right. In a chaotic process, work items move to the right, then back to the left for a little more work, then to the right, then ... it's a mess. A streamlined process only moves a work item from left to right.
Once a process is defined so that the normal flow is left-to-right there may still be exceptions where a work item moves to the left. For example a hypothetical "Step 3" was done wrong and therefore "Step 4 "sends it back to "Step 3" to be fixed. This is called "rework". Reducing the amount of rework is an important goal. It is the least effective use of someone's time. Rework requests should be counted and the most frequent rework causes should be eliminated.
Q: Won't people confuse the 5 milestones with the 3 ways?
A: That is a concern. I originally labeled them A-E instead of 1-5 but then it looked like grades. Being able to say "we got an A" sounds like a good thing, because in school an "A" is a good grade.
I also considered numbering them 0, 1/2, 1, 2, 3. I also considered 0, 1a, 1b, 2, 3.
The problem with all of these schemes is that a team is never "exactly at" a milestone. You are generally "approaching" one or "just past" another. Your team might have one process that is deep into The Third Way and another that is at the first milestone. Do you average the two and say you are at "milestone 3"? Is a grid more appropriate? More thoughts on that below.
I also considered giving the milestones names borrowed from the CMM world. CMM is pretty "old school" but the names fit (see what I mean). I also added colors because life should be colorful.
Again, I'm open to suggestions. Please post a comment to send me email.
How to use this
The Look-For's are a tool. There are many ways to use a tool.
First, you can use them to assess an individual project. You or the team can periodicly review the lists and make an assessment. This helps the team honestly determine where they are because the "look for's" come from an external source.
Second, you can use this model to assess the various functions of a service. A lot of DevOps culture talks about moving from thinking "I manage a machine" to "I provide a service". Service-oriented thinking is, IMHO, the way of the future for IT.
That said, any service has certain "domains" of competencies. A team can do an assessment for each of them. The competancies are probably different for each company but here are the ones that I think are the most common:
- Regular requests.
- Emeregency requests (outages and/or urgent requets).
- Monitoring and Metrics.
- Capacity planning (how we know what resources will be needed in the future).
- Change management (how changes are planned, done, tested).
- New product intro/retire (How well your assimilate [for example] new hardware variations, and depreciate obsolete ones).
Your team might have a different set of domains. For example, a group that is "going global" might be constantly expanding into new data centers. You might add "datacenter turn-up/turn-down" to the list.
It would be a waste of time and effort to get every domain or every service to be Milestone 5. "3 is enough" for certain domains. For example I could see "capacity planning" being "good enough" at milestone 3 if the service is not growing. You just can't let a team "cheat" by declaring "3 is enough" for all domains.
Lastly, you can use this model to do DevOps at a larger scale.
At a large scale you might have 10-20 projects going on at any time. How do you, as a Director or CIO grasp how each team is doing on their move to DevOps? How can you keep "the big picture" without micromanaging? One way is to ask each project leader to keep you abreast of the "milestone" that team has achieved. As Director or CIO you can keep a spreadsheet that shows assessment levels over time. For example, list each project along the left hand side (column A), and then add a column for each month. You can colorcode the entries to get a "heat map" effect to see how the projects are progressing.
Smart project leaders will make the assessment a group discussion and decision. By having teams do self-assessement it helps the team see where improvements are needed. It is much more motivating to self-assess than to be told by a manager an assessment they've chosen for you.
Your job as Director or CTO is to establish company-wide "look for's" so that everyone is uing the same critera.
Lastly if the spreadsheet is publicly viewable it enables teams to compare themselves to other teams. This provides further motivation. It also helps keep teams honest. To be less bureaucratic, you shouldn't have the assessments be too frequent. Quarterly is probably fine.
Some Closing Thoughts
Sometimes we work and work and work and a year later do not have a way to recognize how much progress we've made. We tend to forget the bad days once we've reached the good days. By doing self-assessments we not only get a better understanding of where we need to go, but how far we have come. By recording these assessments in a spreadsheet it becomes a chronical of our progress; something to be proud of.
Again, I want to emphasize that these are "look-for's" not hard and fast rules. You don't have to observe all of them to be able to claim you are at a particular milestone. Not all of them apply to every team. You may also want to add your own.
As Socrates said, "The unexamined life is not worth living." I don't think he did much DevOps but he certainly got this right. By doing periodic assessments it helps us understand where our team is and where we are going. It helps us answer the question, "Are we there yet?"

{kind=link}
{kind=link}
What are the possible steps to pioneer 3-way paradigm in big bureaucratic organization with a big legacy mentality and old-fashioned way of doing things in systems engineering and systems management . How to take off the project and try to fit it into 3-way paradigm and prove the concept to the upper management? We all talk about innovations on the meetings but in the end of the day submit our change records to "/usr/local/changes.txt" by checking it out first with rcs and then appending with the shell history of the change paste.
Thank you